
备注:NPU,Neural Processor Unit,即神经处理器单元。
当矽速科技(sipeed )推出MAIX-II Dock AIoT视觉开发套件的时候,他们向社区求助来对全志 V831的NPU进行逆向工程,从而制作出一个基于NCNN的开源AI工具链。
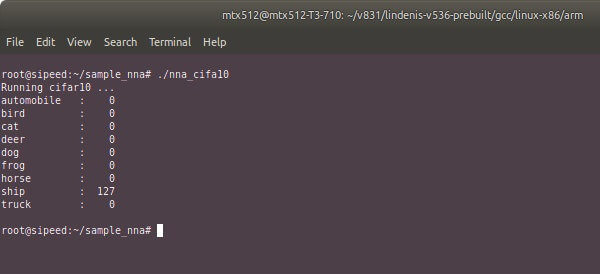
矽速科技之前已经对NPU寄存器进行了解码,所以,Jasbir就为下一步提供了帮助,并得到了一个免费的示例板来进行试用。现在,已经取得了很好的进展,可以使用cifar10对象识别样本来检测船等物体了。
实际上,全志 V831的NPU是基于NVIDIA(英伟达)深度学习加速器(NVDLA)开源架构的定制来实现的。所以,这些就是全志通过矽速科技要求我们从最初的公告中删除的东西。经过逆向工程工作,Jasbir确定了以下关键发现:
- NPU时钟默认为400 MHz,但可以设置在100到1200 MHz之间
- NPU采用nv_small配置(NV小型模型)实现,所有数据操作都依赖于共享系统内存。
- 支持int8和int16,首选int8以提高速度和有限的板载内存(64Mb)
- 64个Mac(Atomic-C*Atomic-K)
- 可从用户空间编程的内存映射寄存器
- 当引用权重和输入/输出数据位置时,需要物理的地址,这意味如果从用户空间访问内核内存,则需要分配内核内存并检索物理地址。
- NPU权重和输入/输出数据遵循与深度学习加速器(NVDLA)专用格式类似的布局,因此必须要先转换为nhwc或nchw等格式,然后再将其传送到NPU。
这些发现使他能够从Arm的CMSIS_5nn库中修改cifar10演示的代码,并删除该过程中所有全志封闭源代码的二进制文件。你可以在GitHub上的v831-npu库中找到源代码,如果你手头有一个全志 V831板,可以查看Jasbir的帖子来了解如何使用。
当前的代码支持卷积计算,偏差加法、relu/prelu、元素操作和max/average池。当然,也还有很多的工作要做,包括开发权重和输入/输出数据转换实用程序,并集成到现有的AI框架中。
还有一个比较好的消息是,这项工作也将会有利于其他基于深度学习加速器(NVDLA)的AI加速器平台,包括Beagle SBC,该平台最近几天才开始进入开发人员手中的。

文章翻译者:Taylor Lee,瑞科慧联(RAK)高级嵌入式开发工程师,有丰富的物联网和开源软硬件经验,熟悉行业主流软硬件框架,对行业发展动向有着敏锐的感知力和捕捉能力。