
通常一个用于 AI 或 ML 推理的典型芯片会包含有一个 NPU、一个 DSP、一个实时 CPU,再加上一些内存、一个应用处理器、一个 ISP 和一些其他 IP 块。Quadric Chimera GPNPU(通用神经处理器单元)IP 则将 NPU、DSP 和实时 CPU 组合到了一个单一的可编程内核当中。
根据 Quadric 的消息来看,这种设计的主要好处是简化了片上系统(SoC)硬件设计和芯片问世后的后续软件编程,这得益于机器学习推理以及前后处理的统一架构。由于该内核是可编程的,因此它未来应该也会成为一种趋势。
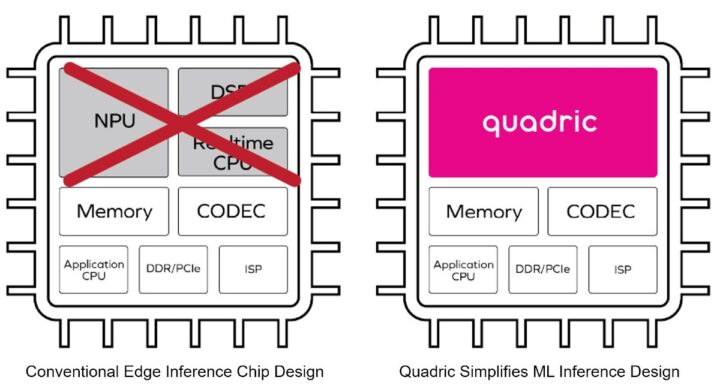
他们一共提供了三个“QB系列”的 Chimera GPNPU 内核供用户选择:
- Chimera QB1 – 1 TOPS 机器学习,64 GOPS DSP 能力
- Chimera QB4 – 4 TOPS ML,256 GOPS DSP
- Chimera QB16 – 16 TOPS ML,1 TOPS DSP
Quadric 表示,Chimera 内核可以与任何(现代)制造工艺一起使用,而且可以在 16 纳米或 7纳米工艺中实现高达 1 GHz 的频率。对于需要更高性能水平的应用,可以将两个或多个Chimera 内核合在一起使用。
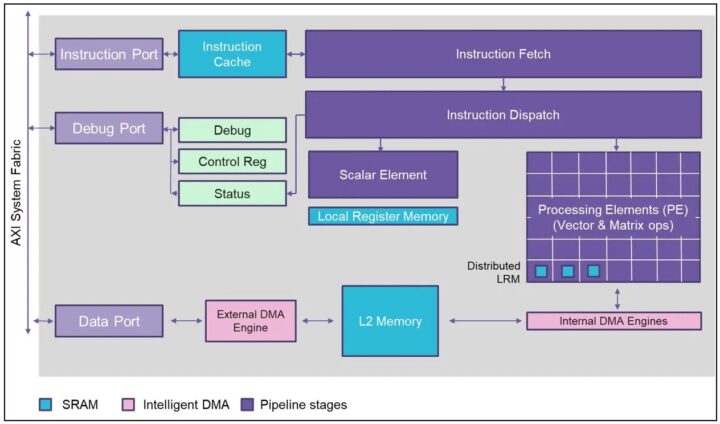
据说 Chimera GPNPU 架构提供的 ML 推理性能与专用 CNN 卸载引擎的效率相似,但它具有完全可编程性和可以运行任何 ML 运算符的能力,这一点对于解决某些问题是至关重要的,比如:数据科学家发现有更好的模型,但是该模型却无法在现有固定函数加速器上运行新的运算符。
Quadric 的架构将神经网络图和 C++ 代码组合到单个软件代码流中,并且只使用了一个工具链用于标量、向量和矩阵计算。其内存带宽也通过一个统一的编译堆栈进行了优化,这有助于降低功耗。软体开发人员只需使用 Chimera Compute Library(CCL,Chimera计算库) API(应用程序编程介面)编写 C++ 内核,然后使用 Chimera SDK(软体开发工具包)编译该内核,即可添加自定义运算符。软件工程师的任务因此得到了进一步简化,因为他们只需要使用一个内核,无需处理多核异构系统。
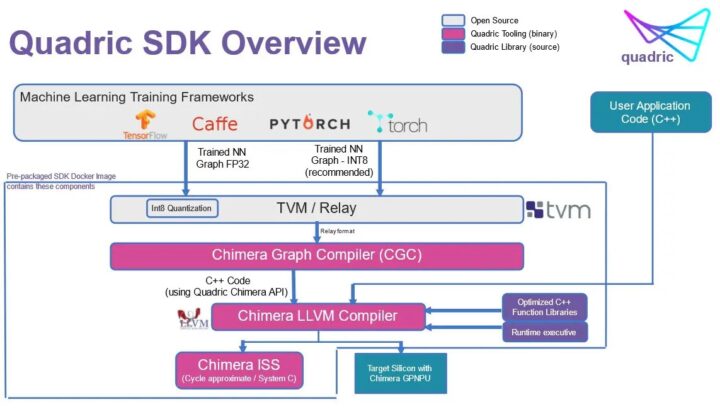
不过,该解决方案可能还需要一段时间才能被芯片实际采用了。虽然 Chimera 架构已经在硅片中进行了测试,但 Quadric 还在寻找今年秋冬天就能使用 IP 评估的芯片设计团队客户。 因此我认为基于 Quadic Chimera 架构的商用 SoC 可能需要一年或更长时间才能上市。其他更多详细信息大家可以在其产品页面和新闻稿中找到。
感谢 TLS 的提示。

文章翻译者:Jacob,嵌入式系统测试工程师、RAK高级工程师,物联网行业多年工作经验,熟悉嵌入式开发、测试各个环节,对不同产品有自己专业的分析与评估。