
BrainChip是一家低功耗高性能人工智能技术的提供商,他们也是神经形态AI芯片和IP商业的生产商。最近,他们宣布推出了 Akida AKD1000 (mini) PCIe 开发板,该开发板是基于该公司的同名神经网络处理器,并依靠脉冲神经网络(SNN) 以一种基于CNN(卷积神经网络)技术传统AI芯片更高效的方式来提供实时推理技术的。
该迷你 PCIe 卡以前出现在基于树莓派或英特尔(x86) mini PC的开发套件中过,它可供合作伙伴、大型企业和 OEM(原始设备制造商)评估使用 Akida AKD1000 芯片。这款产品发布时的新闻也比较简单,就是该卡可以单个或批量购买,而且还能集成到第三方产品中。

BrainChip AKD1000 PCIe卡规格:
- AI 加速器– Akida AKD1000,带有 Arm Cortex-M4 实时内核 @ 300MHz
- 系统内存 – 256Mbit x 16 字节 LPDDR4 SDRAM @ 2400MT/s
- 存储 – Quad SPI 128Mb NOR flash @ 12.5MHz
- 主机接口 – 5GT/s PCI Express 2.0 x1-lane
- 板载 Akida 核心电流监视器
- 其他 – 2 个用户 LED
- 尺寸 – 76 x 40 x 5.3mm(不包括 PCIe 后面板支架)
- 重量 – 15 g(不包括 PCIe 后面板的支架)
该卡还包括后面板的 PC 支架,虽然照片中未显示。BrainChip 方面表示,它将向系统集成商和开发人员提供完整的 PCIe 设计布局文件和材料清单 (BOM),这样他们就能构建自己的设计,或者在 AI 加速卡中实现加入AKD1000,或者也可以作为带有主机板上的协作处理器。该神经网络的创建、训练和测试是通过支持 Tensorflow 和 Keras 进行神经网络开发和训练的MetaTF 开发环境完成的。其中包括一个预训练模型的模型库,以及将 CNN 模型转换为 SNN 的工具模型。
不过,这次该公司没有提供该产品的性能信息,所以我们只好先看看上次公告中的对比图了。
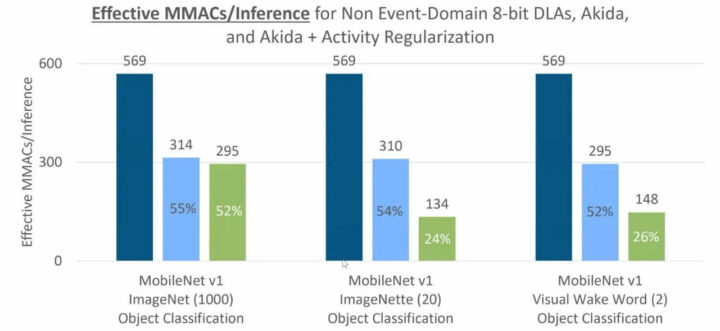
上图主要显示了该解决方案与 CNN 解决方案效率的对比,但没有与更常见的基准(例如以每秒推理数或每瓦特表示的 MobileNet 结果)进行直接比较,这一点让我有点疑惑。但它应该仍然是一个强大的解决方案,正如 BrainChip 所说的,该卡增加了在设备上执行 AI 训练和学习的能力,而且不依赖于云(即数据中心中的 GPU 或 AI 加速器卡)。换句话说,应该是直接可以在该公司提供的树莓派CM4 devkit上以合理的速度进行训练。
BrainChip AKD1000 PCIe 板现在可以预订了,预订价是499美元,交货期是 8 周。不过他们目前每个订单仅限接受10件预定,我想这应该是暂时的,因为该公司已宣布即将于“大批量”生产了。

文章翻译者:Nicholas,技术支持工程师、瑞科慧联(RAK)高级工程师,深耕嵌入式开发技术、物联网行业多年,拥有丰富的行业经验和新颖独到的眼光!