
有时,硬件模块会需要处理它们最初设计时不能处理的任务。例如,神经网络加速器在SoC中变得更加普遍之前,AI推断通常会被卸载到GPU中。
高通AI 研究所最近就展示了一种基于软件的神经视频解码器,该解码器利用骁龙 888处理器中的 CPU 和 AI 引擎,用超过 30 fps 的速度解码 1280×704 的高清视频,而且无需视频解码单元的任何帮助。

现在,神经视频解码器仍在进行中,因为它还是只支持帧内解码,帧间解码还正在研究中。这意味着每个帧目前都是独立解码的,而不像的其他视频编解码器那样,要考虑帧之间的微小变化。
CPU 处理并行熵解码,而解码器网络在骁龙 888 移动平台中的第6代高通 AI 引擎上加速。这部分是通过 AI 模型效率工具包 (AIMET) 开源库处理的,该库可以在 Github上找到。
通过软件获得1280×704视频解码在骁龙 888 上并不是一个令人印象深刻的成就,因为 CPU 在该分辨率和 30 fps 情况下处理 H.264 或 H.265 是没有问题。但是我们必须要考虑神经视频解码的潜在和未来优势,其中包括:
- 比特率和感知质量指标的直接优化
- 简化的编解码器开发
- 内在的大规模并行性
- 高效执行和更新已部署硬件的能力
- 可下载的编解码器更新
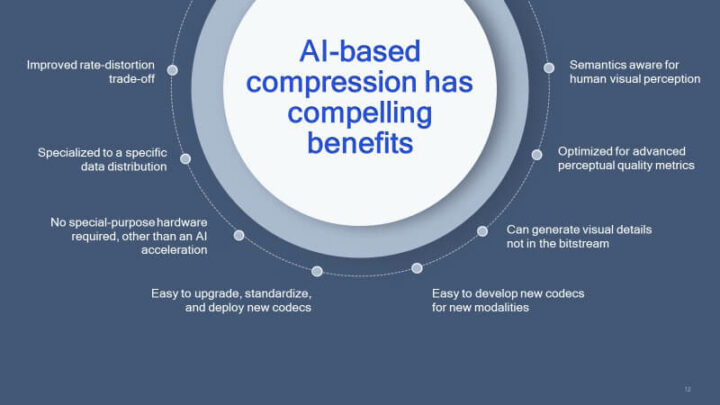
由于,基于 AI 的编解码器能够生成比特流中没有的视觉细节,所以与传统编解码器相比,相同质量或更高质量视频的比特率最终应该都是会更低一些。这也就意味着视频编解码器将会成为软件定义的,无需等待SoC (AV1)中的新硬件解码器来处理,因为任何新编解码器都可以由 CPU 内核和内置 AI 加速器处理,只要它们足够强大。
更多信息你们可以在新闻稿件中找到。

文章翻译者:Jacob,嵌入式系统测试工程师、RAK高级工程师,物联网行业多年工作经验,熟悉嵌入式开发、测试各个环节,对不同产品有自己专业的分析与评估。